
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- np.save()
- Heapreplace
- 빅데이터분석기사
- numpy
- request Method
- 작업형
- 가변매개변수
- 실기
- 비가변매개변수
- matplotlib
- list
- deg2rad
- Python
- heapmerge
- DEEPLEARNING
- Collections
- 빅분기
- BASIC
- np.savetxt()
- 필답형
- kaggle
- os.path.join
- np.load()
- array
- namedTuple
- linalg.solve()
- Math Function
- 빅데이터
- coding
- set_index
- Today
- Total
맞춤형 플랫폼 개발 도전기 (웹개발, 딥러닝, 블록체인)
빅데이터분석기사 실기 Basic 2 (필답형) 본문
필답형이 30점을 차지하기 때문에 준비를 안할 수는 없다. 그래서 중요도가 높다고 생각되는 부분 위주로 정리하겠다.
1. 빅데이터 기술 및 제도
빅데이터 플랫폼 : 수집 → 저장 → 처리 → 분석 → 시각화 과정 (빅데이터에서 가치를 추출하기 위한 일련의 과정) 을 규격화한 기술
빅데이터 플랫폼 구성 요소
- 데이터 수집 : 원천 데이터의 정형, 반정형, 비정형 데이터 수집 (ETL, Crawler, EAI)
* 크롤러 : URL에 존재하는 HTML 문서에 접근해 해당 내용을 추출하고, 문서에 포함된 하이퍼링크를 통해 재귀적으로 다른 문서에 접근해 콘텐트 수집 반복
* EAI (Enterprise Architecture Integration) : 기업에서 운영하는 서로 다은 기종의 Application 및 시스템을 통합하는 솔루션
- 데이터 저장 : 정형, 반정형, 비정형 데이터 저장 (RDBMS, NoSQL)
* RDBMS : 2차원 테이블인 데이터 모델에 기초를 둔 관계형 데이터베이스를 생성, 수정, 관리 가능한 SW이다.
* NoSQL : 전통적인 RDBMS와 다른 DBMS를 지칭하기 위한 용어로서 데이터 저장에 고정된 테이블 스키마가 필요하지 않고, 조인(JOIN) 연산을 사용할 수 없으며, 수평적 확장이 가능한 DBMS이다.
- 데이터 분석 : 텍스트 분석, 머신러닝, 통계, 데이터마이닝 (SNS 분석, 예측분석)
- 데이터 활용 : 데이터 가시화 및 BI, OpenAPI 연계 (히스토그램, 인포그래픽)
* BI(Business Intelligence) : 데이터를 통합/분석하여 기업 활동에 연관된 의사결정을 돕는 프로세스
* 인포그래픽 : Information + Graph 의 줄임말로, 중요 정보를 하나의 그래픽으로 표현해서 보는 사람들이 쉽게 정보를 이해할 수 있도록 만드는 시각화 방법
빅데이터 플랫폼 데이터 형식 (HXCJ)
- HTML : Hyper Markup Language 의 약자, 웹페이지를 만들 때 사용되는 문서 형식이며, text, tag, script로 구성
- XML : eXtensible Markable Language의 약자, SGML(Standard General Markup Language; 마크업 언어를 생성하기 위한 메타 마크업 언어) 문서 형식을 가진, 다른 특수한 목적을 갖는 마크업 언어를 만드는 데 사용하는 다목적 마크업 언어이다. 데이터 표현을 위해 tag를 사용한다. element, attribute, 명령, entity, annotation, CDATE 형식으로 구성되어 있다.
- CSV : Comma Separated Values의 약자로, 몇 가지 필드를 쉼표로 구분한 텍스트 데이터 및 텍스트 파일이다.
- JSON : JavaScript Object Notation의 약자로, 키-값으로 이루어진 데이터 오브젝트를 전달하기 위해 텍스트를 사용하는 개방형 표준 포맷이다.
빅데이터 플랫폼 구축 SW (ROFHS)
- R : 통계 프로그램 언어인 S 언어를 기반으로 만들어진 오픈소스 프로그래밍 언어로, 다양한 패키지를 통해서 강력한 시각화 기능을 제공한다. 빅데이터 분석
- 우지(Oozie) : 하둡 작업을 관리하는 워크플로우 및 코디네이터 시스템(스케줄링, 모니터링)으로 Map Reduce나 Pig 같은 특화된 액션들로 구성된 워클플로우를 제어한다. 워크플로우 관리
* Hadoop : 여러개의 저렴한 컴퓨터를 마치 하나인 것처럼 묶어 대용량 데이터를 처리
- 플럼(Flume) : 이벤트(Event)와 에이전트(Agent)를 활용해 많은 양의 로그 데이터를 효율적으로 수집, 집계 이동한다. 데이터 수집
- HBase : 컬럼 기반 저장소로, HDFS와 인터페이스를 제공한다. 분산DB
- 스쿱(Sqoop) : SQL to Hadoop의 줄임말로 Connector 를 사용해 RDBMS에서 HDFS로 데이터를 수집하거나 HDFS에서 RDBMS로 데이터를 보내는 기능을 수행한다. 정형 데이터 수집
분산 컴퓨팅 환경 SW 구성요소 (맵얀스파하)
- 맵리듀스 : Key-Value 형태의 데이터 처리
Map (Key-Value 형태로 데이터 취합) → Shuffle (데이터 통합해 처리) → Reduce (맵처리된 데이터 정리)
- 얀(YARN) : 하둡의 맵리듀스 처리 부분을 새롭게 만든 자원 관리 플랫폼으로, 리소스 매니저(Master)와 노드 매니저(Slave)로 구성된다. (리노마컨)
리소스 매니저 : 스케줄러의 역할을 수행하고 클러스터 이용률 최적화를 수행
노드 매니저 : 노드 내의 자원을 관리하고 리소스 매니저에게 전달 수행 및 컨테이너를 관리
애플리케이션 마스터 : 리소스 매니저와 자원의 교섭을 책임지고, 컨테이너를 실행
컨테이너 : 프로그램 구현을 위한 격리 환경을 지원하는 가상화 자원
- 아파치 스파크(Apache Spark) : 하둡 기반의 대규모 데이터분산처리시스템이다. 스트리밍 데이터, 온라인 러닝머신 등 실시간 데이터를 처리한다. 스칼라, 자바, 파이썬, R 등에 사용 가능하다.
- 하둡분산파일시스템(HDFS) : 대용량 파일을 분산된 서버에 저장하고, 그 저장된 데이터를 빠르게 처리할 수 있게 한다. 네임 노드(Master)와 데이터 노드(Slave)로 구성되어 있다. (네데)
네임노드 : 파일 이름, 권한 등의 속성을 기록
데이터 노드 : 일정한 크기로 나눈 블록 형태로 저장
- 아파치 하둡(Apache Hadoop) : HDFS와 맵리듀스를 중심으로 다양한 프로그램으로 구성된 Hadoop Ecosystem을 가진다. 클라우드 플랫폼 위에서 클러스터를 구성해 데이터를 분석한다 (Spark, Hive, YARN, Cassandra, Pig)
하둡에코시스템 : 하둡 프레임워크를 이루고 있는 다양한 서브프로젝트들의 모임이며, 수집 저장 처리기술과 분석, 실시간 및 시각화를 위한 기술로 구분할 수 있다.
하둡에코시스템의 수집, 저장, 처리 기술
비정형 데이터 수집 (CFS)
- 척와(Chukwa) : 분산된 각 서버에서 에이전트를 실행하고, Collector가 에이전트로부터 데이터를 받아 HDFS에 저장
- 플럼 (Flume) : 많은 양의 로그 데이터를 효율적으로 수집, 집계, 이동하기 위해 Event와 Agent를 활용하는 기술
- 스크라이브(Scribe) : 다수의 서버로부터 실시간으로 스트리밍되는 로그 데이터를 수집하여 분산 시스템에 데이터를 저장하는 대용량 실시간 로그 수집 기술이다. 최종 데이터는 HDFS 외에 다양한 저장소를 활용 가능하다. HDFS에 저장하기 위해서는 JNI를 이용한다.
* JNI(Java Native Interface) : 자바 코드가 네이티브 응용 프로그램 (HW와 운영체제 플랫폼에 종속된 프로그램들), 그리고 C, C++, 그리고 어셈블리 같은 다른 언어들로 작성된 라이브러리들을 호출하거나 반대로 호출되는 것을 가능하게 하는 프로그래밍 프레임워크이다.
정형 데이터 수집 (SH)
- 스쿱(Sqoop) : 대용량 데이터 전송 솔루션으로, Connector를 사용해 RDBMS에서 HDFS로 데이터를 수집하거나, HDFS에서 RDBMS로 데이터를 보내는 기능을 수행한다. (Oracle, MS-SQL, DB2 같은 상용 RDBMS와 MySQL과 같은 오픈소스 RDBMS를 지원한다.
- 히호(Hiho) : 스쿱과 같은 대용량 데이터 전송 솔루션으로, 현재 깃허브에서 공개되어 있다. 하둡에서 데이터를 가져오기 위한 SQL을 지정할 수 있으며 JDBC 인터페이스를 지원하고, 현재는 Oracle, MySQL 의 데이터만 전송 지원한다.
* Github : 분산 버전 관리 도구인 깃(Git)을 사용하는 프로젝트를 지원하는 웹호스팅 서비스
분산 데이터 저장
HDFS : 대용량 파일을 분산된 서버에 저장하고, 그 저장된 데이터를 빠르게 처리할 수 있게 하는 Hadoop 분산 시스템이다. 범용 하드웨어 기반으로 클러스터에서 실행되고, 데이터 접근 패턴을 스트리밍 방식으로 지원한다.
분산 데이터 처리
Map Reduce : 대용량 데이터 세트를 분산 병렬 컴퓨팅에서 처리하거나 생성하기 위한 목적으로 만들어진 SW 프레임워크이다.
분산 DB
HBase : 컬럼 기반 저장소롤 HDFS와 인터페이스를 제공한다. 실시간 랜덤 조회 및 업데이트가 가능하고 각각의 프로세스는 개인의 데이터를 비동기적으로 업데이트할 수 있다.
하둡에코시스템의 데이터 가공 및 분석, 관리를 위한 주요 기술 (피하머임우주)
데이터 가공 (피하)
피그(Pig) : 대용량 데이터 집합을 분석하기 위한 플랫폼으로 하둡을 이용하여 맵리듀스를 사용하기 위한 높은 수준의 스크립트 언어인 피스 라틴이라는 자체적인 언어를 제공한다. 맵리듀스 API를 매우 단순화시키고, SQL과 유사한 형태로 설계되었다. 하지만 유사하기만 할 뿐, 기존의 SQL 지식을 사용하는 것이 어렵다.
* 피그 라틴(Pig Latin) : 데이터 흐름을 표현하기 위해 사용하는 언어이다.
하이브(Hive) : 하둡 기반의 DW 솔루션으로 SQL과 매우 유사한 HiveQL이라는 쿼리를 제공한다. HiveQL은 내부적으로 맵리듀스로 변환되어 실행된다.
* DW : 사용자의 의사 결정에 도움을 주기 위해 기간 시스템의 데이터베이스에 축적된 데이터를 공통 형식으로 변환해 관리하는 DB
데이터마이닝
머하웃(Mahout) : Hadoop 기반으로 데이터마이닝 알고리즘을 구현한 오픈 소스이다. 분류, 클러스터링, 추천 및 협업 필터링, 패턴 마이닝, 회귀 분석, 진화 알고리즘 등 주요 알고리즘을 지원한다.
실시간 SQL 질의
임팔라(Impala) : Hadoop 기반의 실시간 SQL 질의 시스템이다. 데이터 조화를 위한 인터페이스로 HiveQL을 사용한다. 수초 내에 SQL 질의 결과를 확인할 수 있고 HBase와 연동이 가능하다.
워크플로우 관리
우지(Oozie) : Hadoop 작업을 관리하는 워크플로우 및 코디네이터 시스템으로 자바 서블릿 컨테이너에서 실행된느 자바 웹 어플리케이션 서버이다. 맵리듀스나 피그 같은 특화된 액션들로 구성된 워크플로우를 제어한다.
분산 코디네이션
주키퍼(Zookeeper) : 분산 환경에서 서버들 간에 상호 조정이 필요한 다양한 서비스를 제공하고, 하나의 서버에만 서비스가 집중되지 않도록 서비스를 알맞게 분산해서 동시에 처리한다. 하나의 서버에서 처리한 결과를 다른 서버들과도 동기화하여 데이터의 안정성을 보장한다.
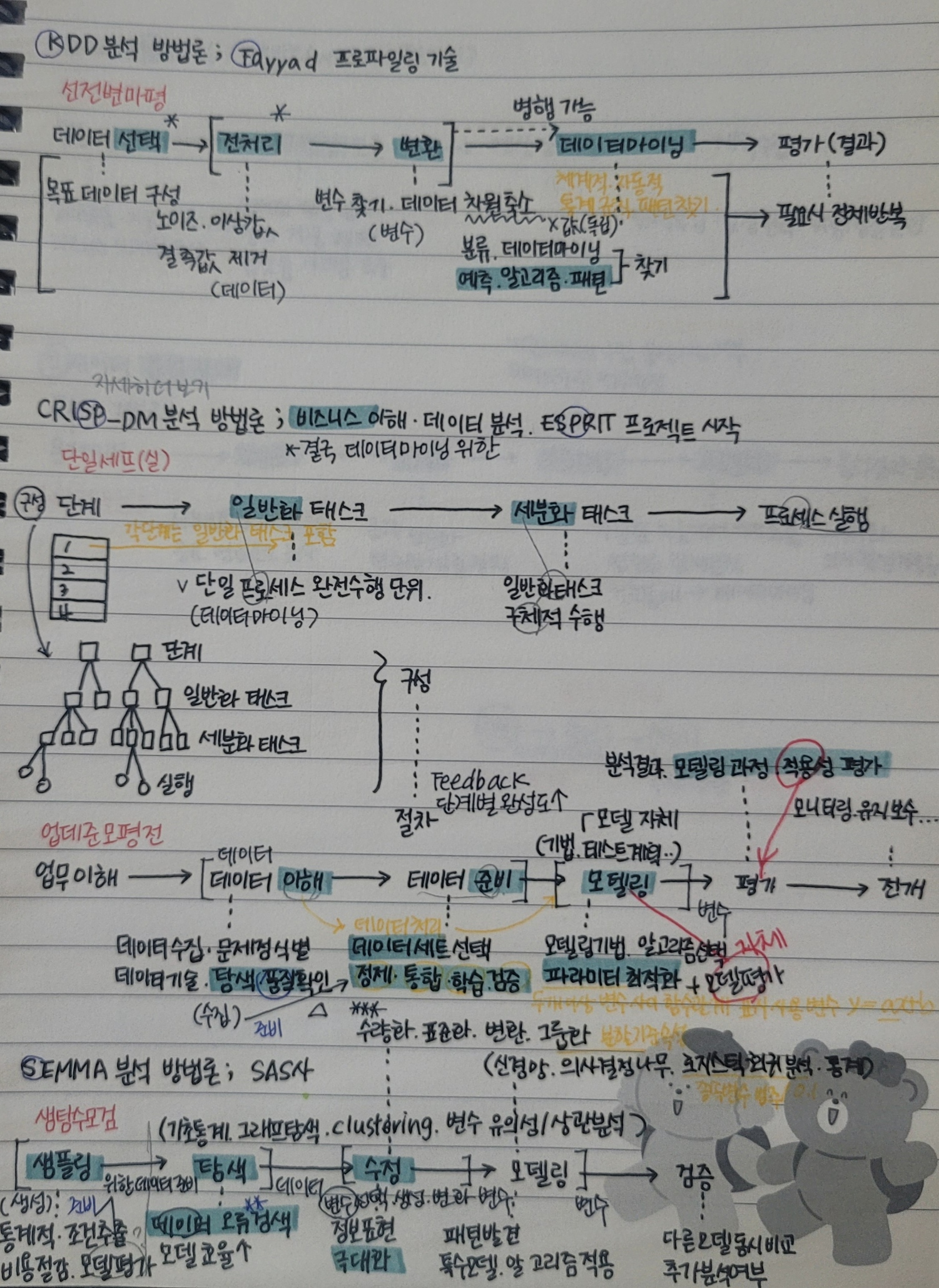
일일히 정리하기에 시간이 많이 소요되는 것 같아 사진으로 첨부하겠다..!








'빅데이터분석기사' 카테고리의 다른 글
| 빅데이터분석기사 실기 Basic 3 (작업형 : Machine Learning Process) (0) | 2021.11.15 |
|---|---|
| 빅데이터분석기사 실기 Basic 1 (작업형 : Numpy, Pandas, EDA, Cleansing) (0) | 2021.11.11 |

