Python으로 Crawling(Parsing), 다운로드하기 : OpenAPI, WebSites, XML, JSON Crawling, Image Download
JavaScript로 Crawling하는 것은 저번에 해 보았다.
JavaScript로 Open API 데이터 가져오기 (영화진흥위원회, 서울 열린데이터 광장)
이전에 본격적으로 데이터를 크롤링해보겠다고 했는데, Open API를 통해 데이터를 가져와 표로 만들어 보았다. Open API를 제공하는 곳은 많지만, 일단, 공공데이터를 가져와보았다. 보통 xml과 json으
katieyoon-the-developer.tistory.com
이번에는 Python으로 Crawling을 해보려 한다.
보통 Crawling이나 Scraping은 대형 포털등에서 통채로 불러올때 쓰는 말이고, 지금 하고자 하는 건 Parsing에 가깝다. 하지만 Crawling 이나 Scraping을 위해서는 Parsing이 기본이 되기 때문에 이렇게 시작해보고자 한다.
그래서 정적인 사이트, 동적인 사이트, 그리고 그 사이트를 Crawling(Parsing)해오면서 어떤 제한사항이 있고 어떻게 해결해야 하는지 알아보고자 한다.
BeautifulSoup를 사용할텐데 BeautifulSoup 파싱 라이브러리를 사용하면 HTML, JSON, XML등을 parsing 할수 있다. 기본적으로 Parser는 HTML, JSON, XML 등 문법 규칙을 바탕으로 웹페이지의 내용을 해석하고, 의미와 구조를 분석하는 프로그램이다.
BeautifulSoup는 import bs4 import BeautifulSoup 로 import해서 사용한다.
BeautifulSoup는 BeautifulSoup(html, 'html.parser')처럼 parser를 이용해서 html, xml, json을 parsing해주며, 내부적으로 document model로 loading해준다.
1. 정적 페이지
네이버 페이지를 예로 들자면,
url = "https://www.naver.com"
response = requests.get(url)
response
# <Response [200]>
response.status_code
# 200
dom = BeautifulSoup(response.text, 'html.parser')
dom

여기서! url을 조립할 수도 있다. 이 말은 Parser를 만들 수 있다는 것인데, 아래처럼 search에 검색할 이름만 바꾸면 원하는 정보를 Parsing해올 수 있어진다.
search="대선"
url = f'https://search.daum.net/search?w=blog&nil_search=btn&DA=NTB&enc=utf8&q={search}'
response = requests.get(url)
dom = BeautifulSoup(response.text, 'html.parser')
이런식으로 html 문서를 읽어온다. 이렇게 만든 dom 객체는 BeautifulSoup 객체이다. 아주 정리가 되어 있지 않은 듯하지만, 데이터 자체가 많아서 그렇지 보기 편하게 정리가 되서 결과가 나온다.
이 객체를 사용해서 사용 가능한 메소드들은 select(), select_one(), text(), attrs(), decompose()가 있다.
select(), select_one()을 통해서 원하는 element를 추출할 수 있다.
select_one()은 내가 CSS selector 로 select 된 첫번째 element 하나를 리턴한다. select()는 내가 CSS selector 로 select한 모든 element(들)의 list를 리턴한다. 심지어 한개도 select 되지 않아도 비어있는 list 리턴한다. select() 뒤에 select_one()을 붙여서 이어 쓰는 것도 가능하다. select() 한 것들의 첫번째 element를 뽑아내고 싶은 경우에 많이 쓴다.
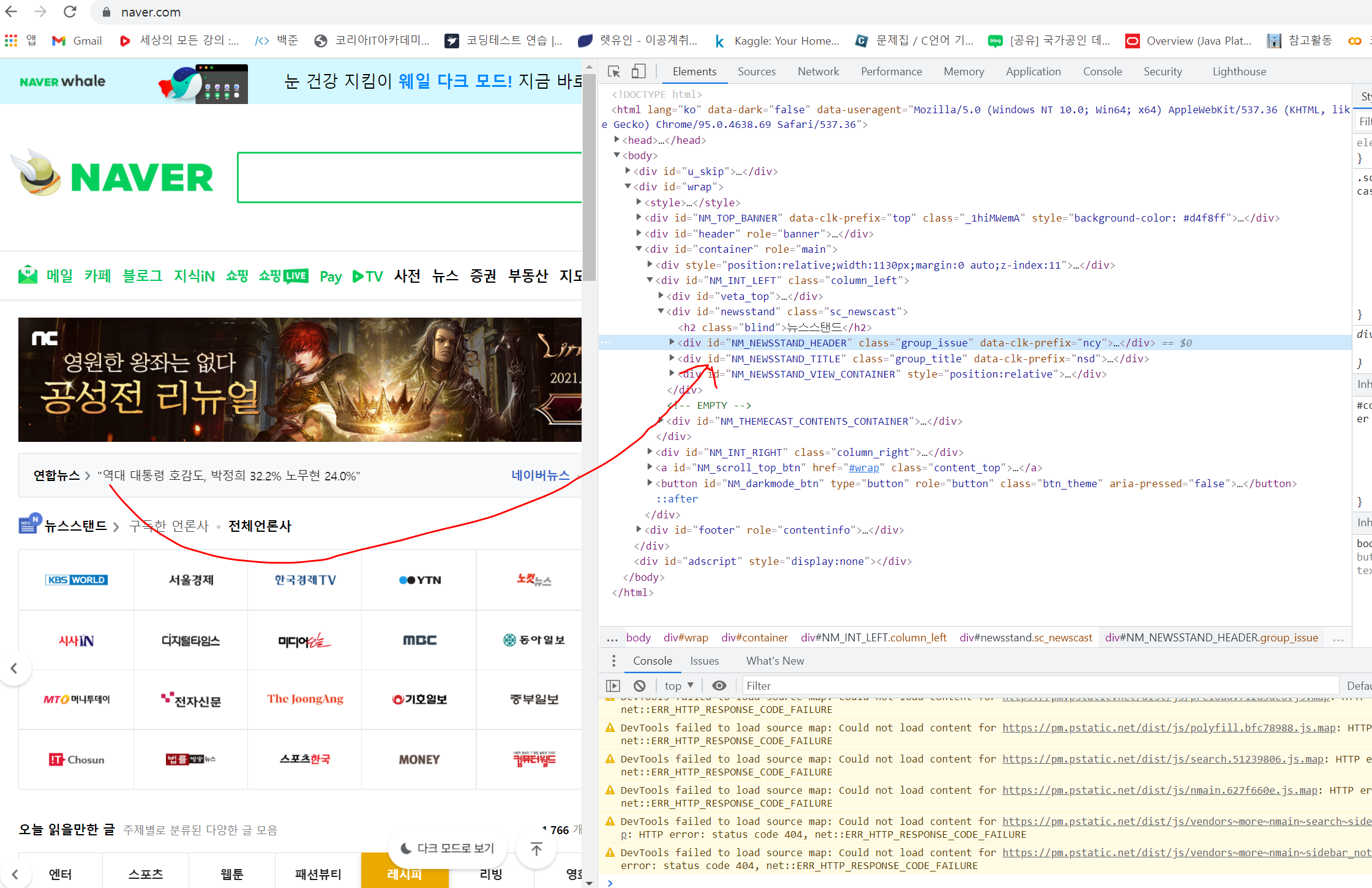
네이버 중에서도 위에 연합 뉴스를 예를 들어서 보면,
elements = dom.select('#yna_rolling .issue')
elements[0]
이렇게 select해서 고른 것중에 0번째가 나온다.
.text는 특정 element 의 content를 가져오는 것으로, 태그는 제거된 형태로 공백을 포함한 내용을 가져온다. 따라서 .text로 내용을 가져왔으면 strip()해 주는 게 좋다. 단, select _one 했을떄만 .text 를 사용해 내용을 가져올 수 있다.
조금만 응용하면 이렇게 뽑아내는 것도 가능하다.
[
element.text.strip()
for element in elements
]
.attrs는 속성을 dict형태로 추출한다. 이 말은 key 값에 접근해 value 값을 뽑아낼 수 있다는 말이다. 대표적인 예로 attrs['href'] 해 오면 주소를 뽑아낼 수 있다.
result = [
{
'뉴스' : element.text.strip(),
'URL' : element.attrs['href'].strip()
} for element in elements
]
.decompose()는 element를 제거한다. 예를 들어 <td><b>[강조]</b>건드리지 마세요</td>를 .select_one('td') 해서 가져왔는데, 저 <b></b> 태그 안에 있는 내용을 지우고 싶다면, decompose()를 사용한다. <b></b> 태그를 지우고 싶다면, element.select_one('b').decompose() 이런 식으로 지워주면 된다.
위에서 뽑아낸 데이터들처럼 list 안에 dictionary 형태로 되어 있으면 pd.DataFrame(result) 를 사용해서 바로 DataFrame으로 만드는 것도 가능하다.

이게 가능하다는 건, DataFrame으로 만든 후 EDA, 정제, 시각화 등을 통해 유의미한 결과 도출하는 등 여러가지가 가능하다는 의미가 된다.
그리고, 얼마나 개발자도구에서 요소를 잘 뽑아낼 수 있는지가 관건이다. 따라서, 웹 크롤링을 하려면 일전에도 말한 적 있듯이 HTML, CSS, JSON, JS 등은 기본이다. 각 tag가 어디를 가리키고 있는지를 확인할 수 있어야, Crawling을 할 수 있기 때문이다.
2. OpenAPI (XML, JSON)
JS로 할 때보다, Python을 사용하면 OpenAPI를 가져오기가 더 쉽다.
예전에 사용했던 OpenAPI token이 기한이 남아있으니, 서울시 공공데이터에서 가져와 보겠다.
key = "토큰(key)" # 토큰 (필수)
date = "20211111" # 언제 데이터를 가져올건지
end_index = 20 # 몇개의 데이터를 뽑아올 건지
req_type= 'json'
url = f'http://openapi.seoul.go.kr:8088/{key}/{req_type}/CardSubwayStatsNew/1/{end_index}/{date}'
response = requests.get(url)
data = response.json()
[
[
row['LINE_NUM'],
row['SUB_STA_NM'],
row['RIDE_PASGR_NUM'],
row['ALIGHT_PASGR_NUM']
] for row in data['CardSubwayStatsNew']['row']
]
url에 들어가야할 필수 요소를 넣고 response.json() 해주면 json 객체는 response.json()을 통해 python 객체로 변환되고, JSON 텍스트는 파이썬 데이터 (list, dict) 로 변환된다.
JSON object { } → Python dict {}, JSON array [ ] → Python list [] 로 바뀐다.

이렇게 간단하게 원하는 데이터를 뽑아낼 수 있다.
XML 역시 단순하다.
req_type= 'xml'
url = f'http://openapi.seoul.go.kr:8088/{key}/{req_type}/CardSubwayStatsNew/1/{end_index}/{date}'
response = requests.get(url)
dom = BeautifulSoup(response.text, 'lxml-xml')
[
[
row.select_one('LINE_NUM').text.strip(),
row.select_one('SUB_STA_NM').text.strip(),
row.select_one('RIDE_PASGR_NUM').text.strip(),
row.select_one('ALIGHT_PASGR_NUM').text.strip()
]for row in dom.select('row')
]JSON이랑 약간 다르지만 JSON은 response.json()하면 바로 Python 객체로 변환되지만, XML은 BeautifulSoup를 이용해서 text를 parse 해주어한다는 점만 다르다. 그래서 기억해야 할 것은 BeautifulSoup(response.text, 'lxml-xml') 이것 하나다. XML은 기본적으로 tag로 이루어져 있기 때문에 .select() 와 .select_one()을 적절히 사용하면 된다. 그리고 select_one을 해서 가져올 데이터를 찾았다면 반드시 .text.strip()해줘야 한다.

이렇게 쉽게 똑같이 만들 수 있다.
3. 동적 페이지
동적 페이지에 들어가면 조금의 제한사항들이 생긴다. 요즘 집값이 많이 올라서 자주 들어가봤던 직방 사이트가 대표적으로 동적 페이지로 구성이 되어있다. JS로 이루어져 있는지(동적 페이지로 구성되어 있는지) 확인할 떄 제일 직관적인 방법은 Chrome의 Web Developer에서 JavaScript 를 Disable 하고 페이지 리로딩해보는 것이다. 일부가 안 읽혀오면 그 부분은 JS로 이루어져 있으며, 동적 페이지라는 것이다. 직방 역시 화면의 데이터(지도, 매물정보)가 읽혀오지 않는다. 그렇다면 어떻게 접근해야 할까?
이런 제한사항들을 일일히 확인해서 해결 방법을 찾아 Crawling하는 것이 Web Crawling에서 가장 중요하다.
그 때는 개발자 도구 (Crawling할 때는 개발자 도구와 함께해야 한다..ㅎ)를 열어서 Network → XHR → name 들에서 동적으로 할당되는 친구들을 확인하고, Request Method와 RequestParameter를 확인한다. 그럼 GET이 아니고 POST 방식인 것을 알 수 있다.
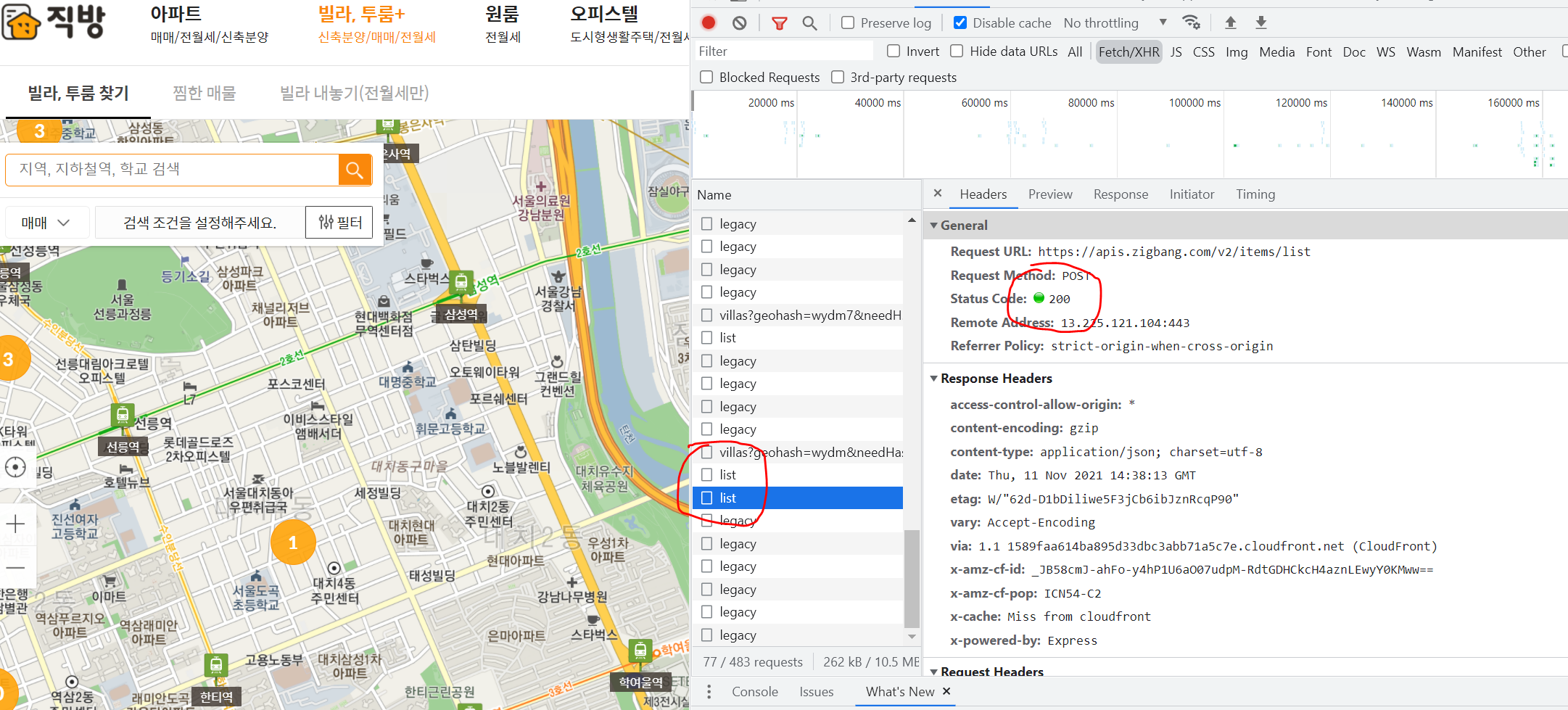
이 경우에는 POSTMAN (GET이 아닌 다른 방식으로 request할 때 test용으로 많이 사용한다.)을 이용해서 Request Payload의 값을 같이 넘긴다.

그럼 이렇게 정상적으로 Request에 대한 결과값이 반환되는 것을 확인할 수 있다. 그럼 이걸 Python으로 어떻게 할 수 있을까? 일단 Request 방식이 POST니까 response = requests.post(url)로 POST 방식으로 request를 보내고, import json 해서 저 Request Payload 값을 담아준 다음 json.loads()를 통해 json 문자열을 python객체 (list,dict 형태로 바꿔줌) 로 바꾼다. 그러면 정상적으로 값을 받아올 수 있다. 그리고 request를 보낼 때는 parameter 로 json = jsondata 이런식으로 body 넘어가야한다. 아래를 보면 이해가 쉬울 것이다.
import requests
from bs4 import BeautifulSoup
import json
jsonstr = """
{
"domain": "zigbang",
"withCoalition": true,
"item_ids": [
29340893,
28969458
]
}
"""
jsondata = json.loads(jsonstr)
response = requests.post(url, json = jsondata)
data = response.json()
[
{
'매물번호' : row['item_id'],
'제목' : row['title'],
'보증금' : row['deposit'],
'월세' : row['rent']
}for row in data['items']
]
이런식으로 데이터를 뽑아낼 수 있다.
보통 동적 페이지에서 못 받아오면, Request Header를 봐줘야 한다. 그래서 user_agent를 넘겨주면 해결되는 경우가 흔하고, key가 없다고 에러 메세지가 뜨면 Request Header를 보고 요구하는 바를 충족시켜주면 된다.
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36',
'x-apikey' : 'iphoneap',
'x-apisecret' : 'fe5183cc3dea12bd0ce299cf110a75a2'
}
response = requests.get(url, headers=headers)
result = response.json()
restaurantList = result.get('restaurants')
[
{
"name" : item.get("name"),
"review" : item.get("review_avg")
}
for item
in restaurantList
]
이외에도 각 웹사이트들이 crawling을 피하기 위해 여러가지 장치를 해 놓기 때문에 상황에 따라 제약사항을 파악하고, 어떻게 crawling이 가능할까 생각해보는게 가장 중요하다. (encoding이라는 옵션을 줘야 하는 경우도 있다.) 하지만 대체적으로 Request Method, Header를 자세히 보면 해결되는 듯 하다. (악용할 생각이라면 절대 하지 않길..)
+) table은 곧바로 DataFrame으로 읽어올 수 있다. 다만, pd.read_html(response.text, encoding = 'euc-kr') 과정이 필요하다. 'utf-8'이라면 encoding은 필요 없다.
4. 이미지/영상 다운로드
네이버 웹툰으로 Crawling 및 이미지 다운로드를 많이 시도해보는 것 같아서 해보았다. 일단, parser 사용법은 동일하고, 다른 점은 이미지, 영상 등은 Binary Data이기 때문에, 다운로드 받을때는 stream = True 옵션을 줘야 한다. 그리고 파일이기 때문에 특정 파일을 'wb'라는 옵션을 주어서 읽어오면 된다. 이건 기본적인 영상이나 이미지를 다운받을 때 사용하는 패턴이다.
for url in moveUrls + imgUrls :
disassembled = urlparser.urlparse(url)
filename = basename(disassembled.path)
print('다운로드 : ', url, ' → ', filename)
response = requests.get(url, stream=True)
if response.status_code == 200 :
with open(os.path.join(dirName, filename), 'wb') as f:
f.write(response.content)네이버 웹툰을 예로 들면 아래와 같다. 이 때 역시 안되는 부분은 Request Header를 살펴보면 해결 방법이 보인다. 네이버 웹툰에서는 referer와 user-agent를 넘겨줘야 한다.
def download_naver_webtoon(titleId, no, padding=0):
pad_no = f'%0{padding}d' % (no) if padding > 0 else no
url = f'https://comic.naver.com/webtoon/detail?titleId={titleId}&no={no}'
response = requests.get(url)
if response.status_code != 200:
print('loading failed')
return
dom = BeautifulSoup(response.text, 'html.parser')
title = dom.select_one('div.tit_area > .view > h3').text.strip()
date = dom.select_one("div.vote_lst .rt dd.date").text.strip()
img_elements = dom.select("#comic_view_area .wt_viewer img")
img_urls = [
element.attrs['src']
for element in img_elements
]
dirName = re.sub('[\\\\/:*?"<>\|.]', '-', f'{titleId}({date})')
saveDir = os.path.join(base_path, f'{pad_no}_{dirName}')
if not os.path.exists(saveDir):
os.mkdir(saveDir)
headers = {
'referer' : url,
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
for img_url in img_urls:
disassembled = urlparser.urlparse(img_url)
filename = basename(disassembled.path)
savePath = os.path.join(saveDir, filename)
print('download : ', img_url, '->', savePath)
response = requests.get(img_url, headers=headers, stream=True)
if response.status_code != 200 :
print('fail')
continue
with open(savePath, 'wb') as f:
f.write(response.content)
print('success')
titleId = 작품id
no = 작품회차
download_naver_webtoon(titleId, no, padding=4)지날수록 느끼겠지만, Crawling 방식은 비슷하다. 제약사항을 파악하고, tag의 역할과 attribute가 뭔지 파악할 정도의 insight만 있으면 쉽게 할 수 있다. (참고로 urllib의 모듈의 urlparser.urlparse로 url을 분리시켜 내가 원하는 부분을 뽑아낼 수 있다)
Go가 Web Crawling을 어마무시하게 빨리 한다고 알고 있어, 차후에는 Go를 이용해서 Crawling하고 데이터를 가공하는 연습을 해보려 한다. (지금은 Setting만 끝난 상태이다)